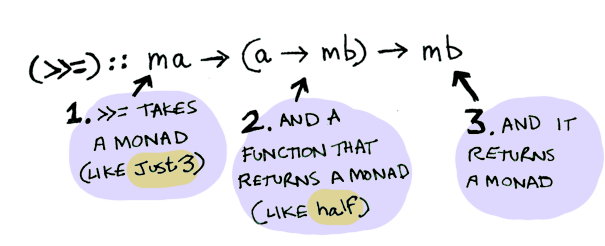
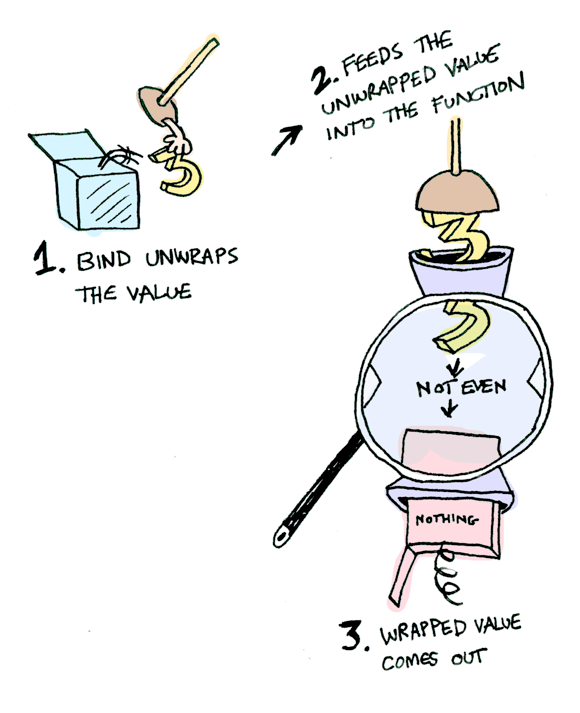
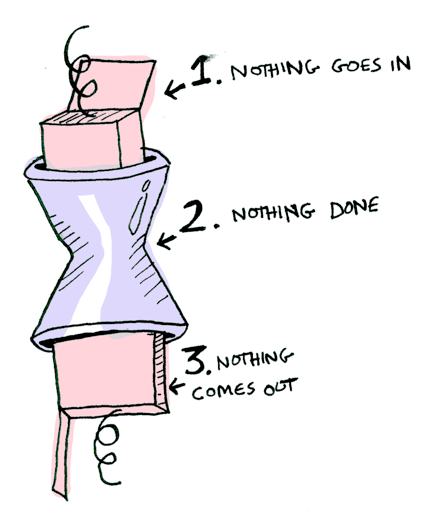
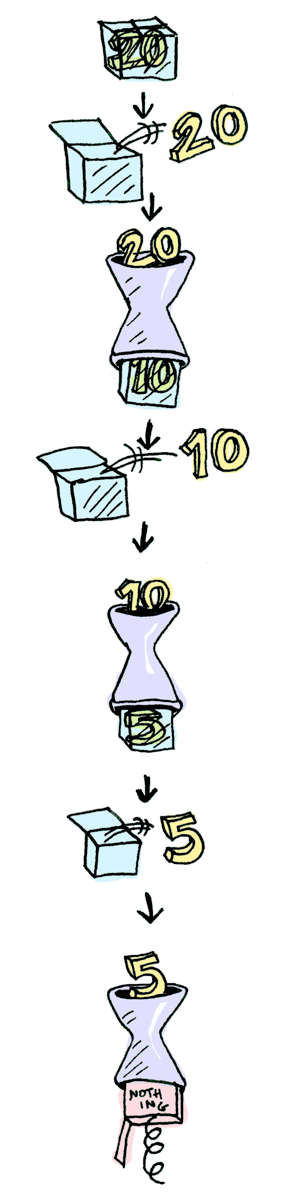
소프트웨어 기초 (Software Foundations) 번역
- http://swlab.jnu.ac.kr/wordpress/2017/08/22/software-foundations-with-coq/
- 2017년 9월 대학원 강의로 소프트웨어 기초를 진행하면서 번역한 것을 위 웹 주소에 올려놓았습니다.
[ 교재 ]
New volumes : Vol 1. Logical Foundations, Vol 2. Programming Language Foundations
- https://softwarefoundations.cis.upenn.edu/
[ 강의 로드맵 ]
Vol 1. Logical Foundations : Preface
Vol 1. Logical Foundations : Functional Programming in Coq (Basics)
Vol 1. Logical Foundations : Proof by Induction (Induction)
Vol 1. Logical Foundations : Working with Structured Data (Lists)
Vol 1. Logical Foundations : Polymorphism and Higher-Order Functions (Poly)
Vol 1. Logical Foundations : Logic in Coq (Logic)
Vol 1. Logical Foundations : Inductive Defined Propositions (IndProp)
Vol 1. Logical Foundations : Simple Imperative Programs (Imp)
Vol 2. Programming Language Foundations : Program Equivalence (Equiv)
Vol 2. Programming Language Foundations : Hoare Logic, Part I (Hoare)
[ 전술 목록 : Ch. More Basic Tactics in Volume 1 ]
- intros: move hypotheses/variables from goal to context
- reflexivity: finish the proof (when the goal looks like e = e)
- apply: prove goal using a hypothesis, lemma, or constructor
- apply... in H: apply a hypothesis, lemma, or constructor to a hypothesis in the context (forward reasoning)
- apply... with...: explicitly specify values for variables that cannot be determined by pattern matching
- simpl: simplify computations in the goal
- simpl in H: ... or a hypothesis
- rewrite: use an equality hypothesis (or lemma) to rewrite the goal
- rewrite ... in H: ... or a hypothesis
- symmetry: changes a goal of the form t=u into u=t
- symmetry in H: changes a hypothesis of the form t=u into u=t
- unfold: replace a defined constant by its right-hand side in the goal
- unfold... in H: ... or a hypothesis
- destruct... as...: case analysis on values of inductively defined types
- destruct... eqn:...: specify the name of an equation to be added to the context, recording the result of the case analysis
- induction... as...: induction on values of inductively defined types
- inversion: reason by injectivity and distinctness of constructors
- assert (H: e) (or assert (e) as H): introduce a "local lemma" e and call it H
- generalize dependent x: move the variable x (and anything else that depends on it) from the context back to an explicit hypothesis in the goal formula
[전술 목록 : Ch.3 from Coq in a Hurry ]
'Coq 증명기' 카테고리의 다른 글
| 타입이 다른 원소들의 리스트 (Heterogeneous Lists) (0) | 2014.08.26 |
|---|---|
| [Coq 증명기] 콕, 빨리 빨리: 8장 귀납적 성질 (0) | 2014.08.09 |
| [Coq 증명기] 콕, 빨리 빨리: 7장 콕 시스템의 숫자 (0) | 2014.08.09 |
| [Coq 증명기] 콕, 빨리 빨리: 6장 새로운 데이터 타입 정의하기 (0) | 2014.08.09 |
| [Coq 증명기] 콕, 빨리 빨리: 5장 리스트 프로그램의 성질을 증명하기 (0) | 2014.08.09 |